
Apps that ship themselves over ssh
Moving a typed, reactive app's source of truth onto another machine — with nothing between you and it but ssh, and nothing installed on the far end.
In the last post I pulled the wiring out of Kolu and into a framework. @kolu/surface gave me five shapes — Cell, Collection, Stream, Event, Procedure — declared once and read three ways, with snapshot-then-deltas on the wire so a fresh client lands correct and stays correct through a dropped connection. The whole thing rode a WebSocket from the browser to a Bun server, and the server owned the truth.
This post is about what happened when the truth moved to a different machine.
The itch was concrete, not architectural. Kolu has an open feature request — remote terminals over ssh — and the obvious way to do it is the way that quietly ruins a codebase. You braid local-vs-remote into every domain: a RemoteGitProvider twinning the local one, then a RemoteAgentProvider, then a RemoteFsProvider, on forever, each carrying its own copy of “are we here or there.” I didn’t want to pay that tax. I wanted to know the right shape before paying anything.
The shape
The whole thing came down to four decisions, and they forced themselves on me roughly in that order.
One backend, one boundary
The pivot that collapsed everything was a single Backend interface that owns the per-terminal world — the PTY, every metadata channel, the fs and git ops. Once that exists, “remoting a domain” stops being work. There’s no RemoteGitProvider. There’s one RemoteBackend that proxies the whole backend protocol across one transport boundary, and git is just one of the things on the other side of it. You cross the boundary once, not once per domain.
And the agent on the far end is the same binary as the server. kolu serve runs with a LocalBackend. kolu --stdio runs the identical code with oRPC’s transport set to stdio instead of a WebSocket. The agent has no remote-specific logic at all — it’s just another oRPC peer that happens to be talking over a pipe. LocalBackend and RemoteBackend turn out to be the same class, parameterized by which link they’re built with: stdio, loopback, or websocket. Going remote is a constructor argument, not a rewrite.
// agent, far end: same router, transport set to the pipe — this is `kolu --stdio`
serveOverStdio({ router });
// parent, near end: one ssh subprocess, a typed client out the other side
const client = await getHostSession({ host, resolveDrvPath, binary }).pin();
client.system.get({}); // identical oRPC the browser calls over a WebSocketThat’s the property the whole previous post was secretly setting up. An in-process contract is a network protocol in disguise. Shape the in-process direct link the way it would have to look riding ssh — full snapshot first, then deltas, typed framing, race-free attach — and the day you put a socket under it, the consumer code doesn’t notice. I’d been building the toaster to fit a socket that wasn’t in the wall yet.
The transport is the ssh pipe
A transport needs a binary on the other end. How does it get there? Zed does it with a three-strategy dance — SFTP, a CDN, fallbacks — to land the right binary on the remote. I didn’t want a dance. I wanted Nix. One content-addressed closure, served the same to local and remote, realised on demand. The slogan fell out of the design almost on its own: if you can ssh in, you have a live typed app on that host. Nothing installed for good, no inbound port opened, no daemon configured. The transport is the ssh pipe. Stdout is the protocol.
That last sentence is more load-bearing than it reads. In --stdio mode stdout literally is the oRPC channel. The first time I ran it, the client choked: SyntaxError: Unexpected token «. The agent’s pino logs were going to stdout, and JSON.parse hit a log line mid-stream and died. So you detect --stdio at module load and send every log to fd 2. Write one stray byte to fd 1 and you corrupt the wire. It bit more than once, so the transport documents it now.
nix copy does not cross architectures
This is the wall everything after it is shaped around. I build the agent on my Mac. I nix copy the closure to a Linux host. The copy succeeds. The realise succeeds. Then it dies with Exec format error. A Linux box can’t run a darwin bash, and no remote-builder config changes that, because by the time exec happens the architecture is already baked into the closure I shipped. nix copy will happily move a binary your remote can never run.
The fix reorganized the whole bootstrap. Don’t ship the outputs. Ship the instructions. The agent is described by a derivation — a .drv, architecture-neutral build instructions, not architecture-specific binaries. The parent evaluates the build once, copies the derivation over with nix copy --derivation, and the remote realises its own target-arch binary against its own Nix with ssh $host nix-store --realise. Evaluate once at the parent. Realise on each host. Cross-arch went from the thing that broke to the thing the whole provisioning layer is organized around.
parent: nix copy --derivation --to ssh-ng://$host $drvPath # ship build instructions
remote: nix-store --realise $drvPath → /nix/store/…-agent # build, target-arch
remote: nix-store --realise $out --add-root <link> --indirect # GC-pin while live
parent: ssh $host $agentPath/bin/agent --stdio # run it; stdout is the wireThe tempting alternative — make it “most Nix-native” by having each remote evaluate the whole flake against its own currentSystem — I tried and threw away. It deletes some code, but it inverts the clean property (parent evals once, remotes only realise) and it breaks just dev from a Mac against a Linux host on an uncommitted working tree, which is the exact dev loop this work exists to support. “Most Nix-native” turned out to mean “moves the work to the worst place for it.” Sometimes “do the right thing even if it’s a bigger change” resolves to the smaller change, and finding out the bigger one doesn’t hold up is itself the work.
There’s a smaller trap inside the big one. A host added at runtime — by clicking a button three minutes after launch — isn’t known at Nix-eval time, so you probe its system live. The obvious probe, ssh $host uname, is wrong: Nix’s system setting, not the kernel’s report, decides what builds, and the two differ on Rosetta and emulated boxes. So you ask the remote’s own Nix: ssh $host nix-instantiate --eval --expr builtins.currentSystem. No new dependency, because the remote already has Nix. That’s the whole premise #1009 .
The demo’s only job
Now I had a transport. The next question was altitude: did the stdio plumbing belong in Kolu, or in the framework? I learned the answer the hard way. One PR bundled a hand-rolled stdio transport inside the server package, and the next one had to delete it and lift it into surface. So I went back and inserted a phase ahead of the migration — land the framework primitives first, then let Kolu consume them — which spared about 300 lines that would otherwise have been written and then deleted. The most valuable PRs in this project are the ones that never merged. You prototype to learn, then build a clean ladder to ship. Surface grew two narrow link adapters, stdio and loopback, and Kolu deleted about 400 lines of framing and per-channel relay #1059 . The framework eats the cost so Kolu stays small.
But generic-for-Kolu isn’t generic. The test of whether the new primitives were truly framework-shaped, and not Kolu-shaped in disguise, was a demo with one bar to clear: what’s the benefit over running this locally?
Notes-over-ssh failed — why keep your notes on a box you ssh into? Log-tail failed in a more interesting way: there’s no universally tailable file left in 2025. macOS moved to unified logging, Linux moved to journalctl, and ~/.bash_history only writes on shell exit. The thing everyone supposedly has doesn’t exist anymore.
The winner was a remote process monitor. /proc on Linux, sysctl and ps on darwin — universal, always readable, always changing, zero setup. The whole thing is one small surface:
defineSurface({
cells: { system: { schema: SystemSchema } }, // load avg, mem, uptime, os
collections: {
processes: { keySchema: PidSchema, schema: ProcessSchema }, // { user, cpuPct, memPct, command }
},
procedures: { "process.kill": { input: KillSchema } }, // (pid, signal)
});It’s undeniably better remote: the box you want to ask “what’s eating your CPU” is the one across the ssh connection, which is exactly the box you can’t already see. That demo became drishti #984 .
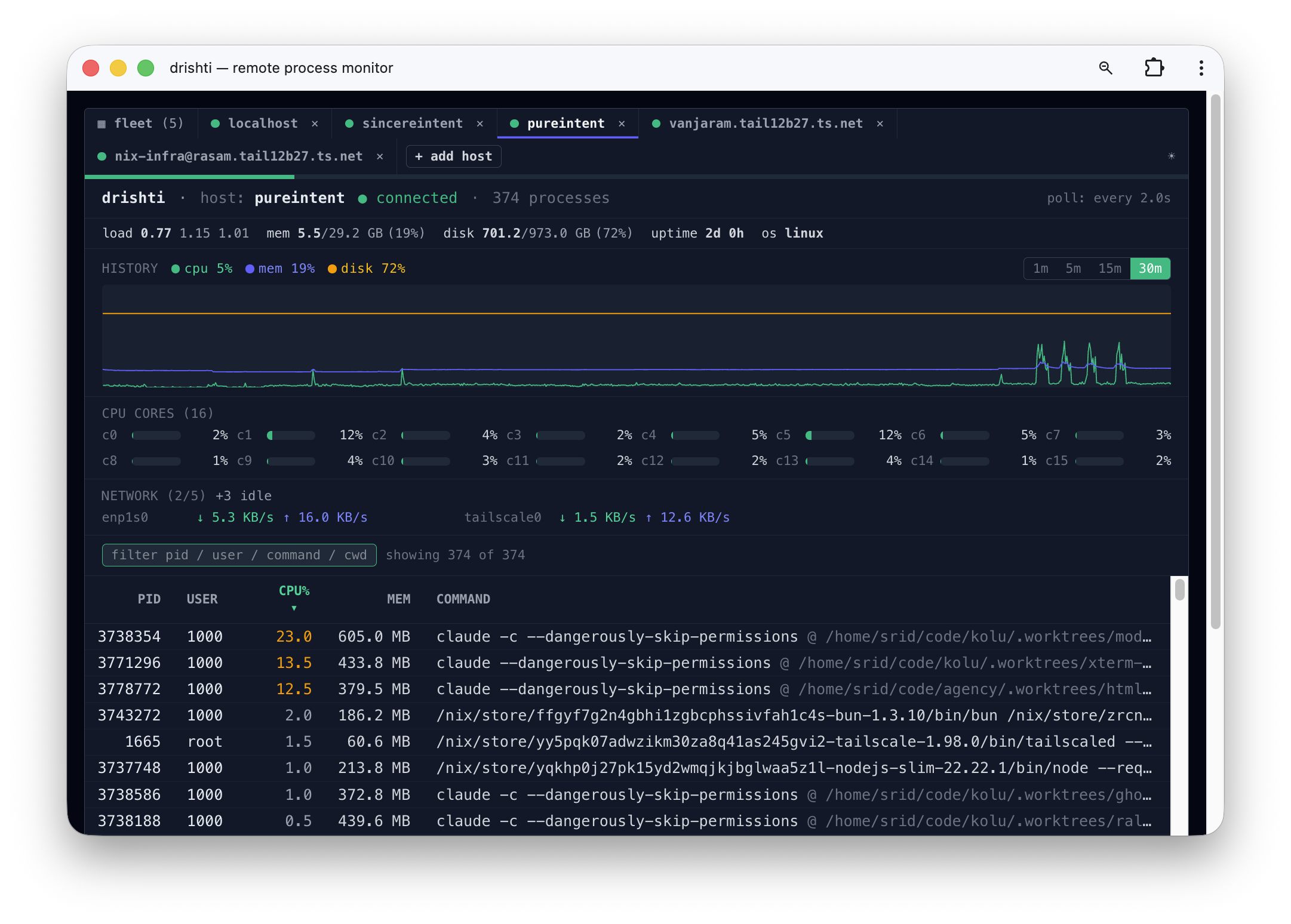
What production taught me
drishti is a real app with real users on MacBooks, and real users break your assumptions one at a time. Almost everything I learned after the prototype worked, I learned from a host misbehaving.
localhost is the worst host in the fleet
The first one made me laugh. localhost timed out. “It needs no network, it should just work” — and it didn’t. Thirty-second timeout, “transport up, no first RPC.” The mistake in my head was treating “no connection” as “no handshake.” Even loopback runs the uniform lifecycle: resolve system, realise, spawn over stdio, wait for the first RPC frame. localhost skips the network and nothing else.
And localhost is cursed in three ways at once. It’s the most-loaded box in the fleet, because the agent runs on the very machine it’s measuring. It’s often darwin, which forks ps and lsof and netstat over hundreds of PIDs where Linux just reads /proc. And it gets served last, so the parent’s first RPC frame sat unread in the child’s stdin until the whole process table finished enumerating. The fix: serve the cheap system cell first, enumerate the process table lazily on the first poll tick. Sub-second handshake no matter how many processes. “Just raise the timeout” was a band-aid over a real bug. The one host that should just work is the worst case in your fleet.
The laptop closes its lid
Then the roaming problem, the one that taught me the most. You close the lid at home. You open it at a café. Every host lands in failed, each one wanting a manual Reconnect. The give-up gate was calibrated for a config fault: if your auth is wrong, retrying is pointless, so give up after a few tries. But the only fault a roaming laptop ever has is a network fault, and for a network fault retrying is the entire point. Café Wi-Fi — captive portal, then DHCP, then DNS — takes twenty to forty seconds to settle, so I was declaring hosts permanently dead before the network was even usable.
So every failure now carries a cause: network or remote, classified by which phase failed, never by string-matching error text. Network faults retry forever at a 60-second cap, so a roaming laptop heals itself. Remote faults — a non-zero nix copy, a user who isn’t in trusted-users — go terminal after five tries and fail loudly. failed now means one thing: a human has to fix something #1039 . And the classification had to live in Kolu, which owns the retry loop, not be reconstructed in drishti by grepping “gave up after” out of log lines across a package boundary. That was the wrong seam.
Wake-up has a sequel. After sleep, the far end has dropped the TCP socket, but the local ssh child won’t notice until keepalive fails about thirty seconds later — so the link reports “connected” while it’s lying. reconnect() deliberately won’t disturb a live link, but this link only looks live. So a second verb, recheck(), force-cycles whatever is there including a “connected” one, and a wake detector — a one-second wall-clock-gap watcher — fans it across the pool, shrinking that thirty-second stale-green window to about one #1078 .
The bug that took down the fleet
The nastiest bug in the whole arc isn’t in my code. It’s in the ergonomics of the client.
The oRPC client is a Proxy that forwards every property access as a procedure path — including .then. So the client is thenable, and await session.currentClient() hands back a fresh object every call. Which means any identity check on the awaited client — if (client !== previous) — is always true. In production, one killed ssh child sent the reconnect loop into a busy-spin at event-loop speed: about two million iterations in two minutes, server pinned at 70% CPU, HTTP dead. And it couldn’t recover, because the spin starved the very exit handler and backoff timer that would have recovered it. One dead ssh child took the whole fleet server down.
The fix is to compare the stable clientPromise reference — one per spawn, null between death and respawn — instead of the awaited value #1064 . The twist I keep thinking about: this bug had been masked by an earlier one. The stdio pump used to hang on a dead transport, which was an accidental brake. When I correctly made it fail fast #1060 , I took the brake off and the latent spin showed up. Fixing one correctness bug can resurrect another.
The same theme ran through the Reconnect button, which was a silent no-op. A nix copy failure threw before any ssh child existed, so three separate guards each read the stale state as “spawn in flight” and returned quietly — while the admin RPC still resolved {ok: true}. Three error-hiding mechanisms stacked into one lie. The rule that came out of it is short. Errors must reach the user, never the void #1053 .
Hardening, and then features for free
Two more walls, both the kind you only hit in production.
A remote nix-collect-garbage could delete a live agent, because the realised closure had no GC root. The fix is nix-store --realise <path> --add-root <link> --indirect — --indirect is mandatory, since the ssh user isn’t root — with one fixed-name “latest” symlink per agent, so each realise overwrites it and the old output drops out of the root set. Generation management for free #1067 . (A sibling fix: ssh keepalives, threaded into both the ssh I spawn and the NIX_SSHOPTS env that nix copy forks out of my control, so a host that degrades mid-build bounds death instead of slowness, no matter how long the build’s stdout stays quiet #1071 .)
The one that surprised me most: the agent’s closure was secretly the whole app. Every drishti rebuild — even a one-line CSS tweak the agent never imports — rotated the agent’s .drv hash, so every remote repaid a ten-minute cross-arch closure copy on the next reconnect. The obvious fix, giving the agent its own workspace package, was inert on its own: bun2nix bakes the entire app source tree into a dependency cache, so a client-only edit still rotated the hash. You had to also strip the app member out of that cache. And the only way to catch any of it is to check drv-stability against a committed tree with --no-eval-cache, because a filesystem-only fileset probe reports a false pass that never exercises the bun2nix edge.
Once the transport was solid, features rode the typed contract almost mechanically. Per-NIC network I/O, rate computed agent-side. Disk percent-full. Cache-aware memory — with its own darwin gotcha, since Apple Silicon uses 16 KB pages, not 4 KB, so a hardcoded 4096 reports memory four times too small. Parent-owned history rings, so a 30-minute sparkline on a dozen fleet cards costs subscriptions, not connections, and survives a reload. ProxyJump bastion support with zero code, because it shells out to plain ssh and inherits your ~/.ssh/config. Each one was a few lines against a surface, not a feature project.
A new class of apps
The status quo for remote monitoring and control is an ops project. Datadog, Prometheus node_exporter, Telegraf — you install an agent on every target, open and secure an inbound port or run a collector daemon, manage config and credentials and version skew, and only then get data. Usually flat metrics, too, not a typed contract you program against.
The oRPC-over-ssh model deletes all of it. Nothing installed for good — the agent is a Nix closure realised on demand, GC-pinned only while it’s live. No listening port — the transport is the ssh pipe. No daemon to configure — the one requirement on the remote is a nix-daemon that trusts your user. And you inherit your whole existing ssh world for free: keys, ~/.ssh/config, ProxyJump bastions, connection multiplexing. The same reactive primitives I use locally — useCell, useCollection, snapshot-then-deltas, race-free attach — work across an ssh process boundary unchanged.
So “build a remote monitoring or control tool” collapses from a multi-week ops project into an afternoon, because the source of truth just lives on another machine and the plumbing is identical. The apps it makes cheap are install-free, ephemeral, typed, and reactive. drishti is the flagship of the class: htop for your whole fleet, with nothing installed on the remote.
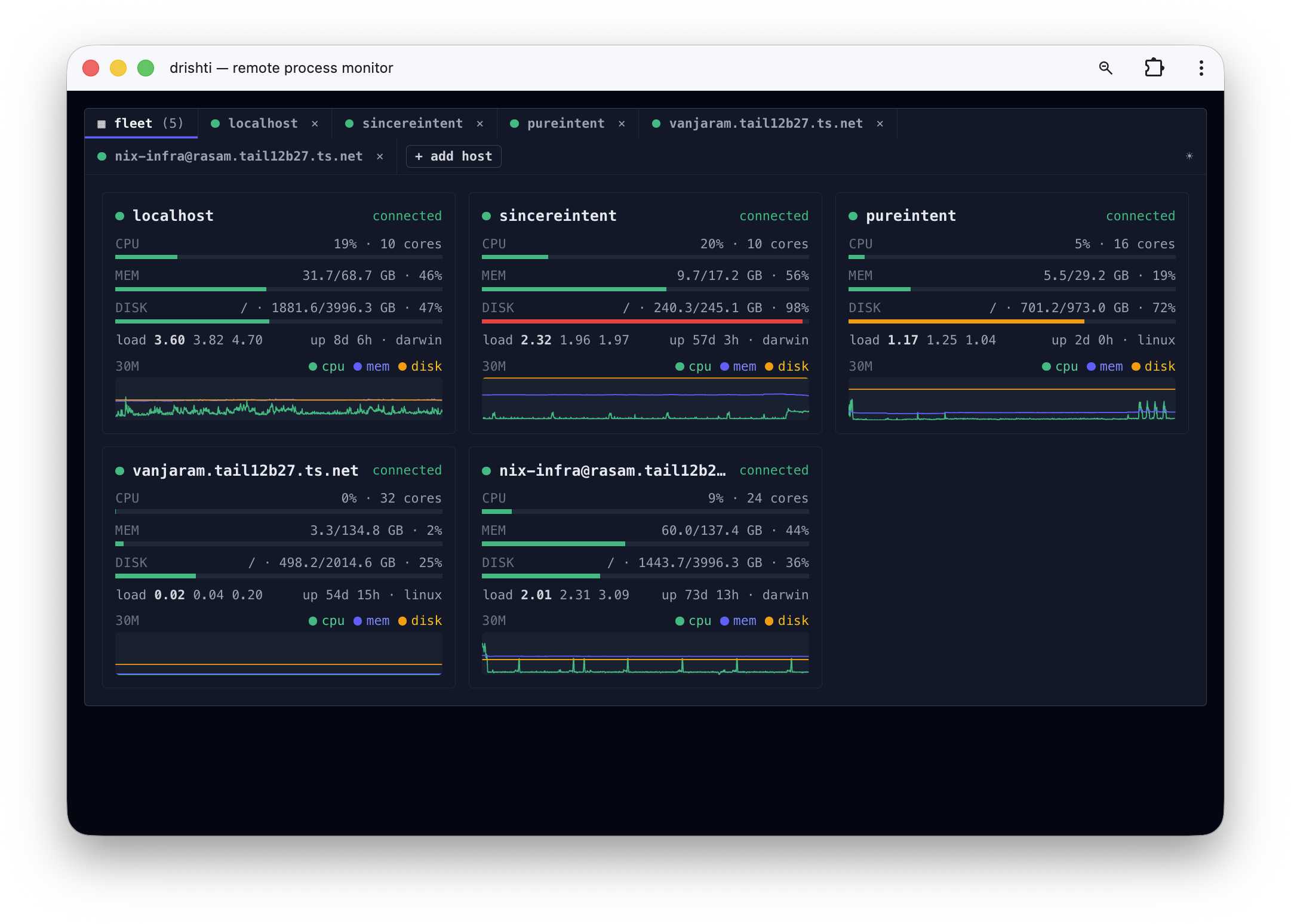
Or watch it move — the multi-host fleet view and a live htop drill-down, all streaming over ssh:
Watch drishti in action — the multi-host fleet view and a live htop drill-down, all over ssh.
The proof that the framework is really generic — and not Kolu in a trench coat — is that it graduated back out. @kolu/surface, now MIT to match oRPC #999 , is consumed by drishti through npins: a completely different app, sharing none of Kolu’s terminal domain, plugged into the same reactive transport. Surface came out from under Kolu, a different app plugged in, and surface never noticed the domain changed.
The demo was never the point. The process monitor was a falsifiability test that happened to be useful. The point is where it goes after. mini-ci, a CI-runner TUI speaking oRPC over stdio #1073 , was one rung in the ladder that de-risks the transport before any UI touches it. Kolu’s own RemoteTerminalBackend — #951 , the thing that started all this — collapsed nine per-terminal metadata channels into one keyed collection plus one data stream at the cross-process boundary. And then whatever you build the week the rule clicks. If you can ssh in, you have a live, typed, reactive app on that host. You didn’t have to install, open, or configure a thing to get it.
How hard is that?
@kolu/surface · the stdio + loopback link adapters · @kolu/surface-nix-host, the ssh provisioning layer · drishti · oRPC